By Anurag Malakar, PGDBA Batch-5 (2019-21)
The year 2005 | A regular morning in a middle-class Indian’s life
The middle-aged mom heaved a sigh of relief, having just sent off her kids on the school bus. It’s been a busy morning for her; she had woken up early to cook food for her husband and the two darling-turned-devils of her eyes. She returns upstairs and spends the rest of the morning preparing lunch for her kids who’ll soon be home, arguing with her maid, and reminding the security guard for the umpteenth time to call a plumber to repair the leaky faucet in her kitchen. She watches a repeat of her favorite TV show on Star Plus for a while before going to the market and buying fresh vegetables and bread for the next day.
The year 2019 | A technology-enabled morning in an aspirational Indian’s life
The father sits down on the sofa in the living room, exhausted after an early morning run. He checks his Fitbit and grins as the tiny screen highlights that his mean speed was 25% higher than last month’s average. After freshening up, he wakes up the kids and walks over to the living room. While pouring milk and cereal into three bowls, he observes that the pack of cereals is almost empty. His kids enter the living room and call out to Alexa to play their customized playlist of morning songs, and she dutifully obliges. He whips out his phone, opens WhatsApp and video calls his better half who’s away on a business meeting. The happy family reunion is interrupted by the sound of the doorbell, which suggests that Amazon will timely deliver the new toy the younger kid had been demanding for the past week. The dad checks the time, gets dressed quickly, and books a cab while tying his shoes. He drops his kids off to school and orders their favorite pack of cereals on Grofers. He calculates that he has just about enough time to finish the Netflix special that he had dozed off while watching last night. The app’s proprietary algorithm that incessantly analyzes his viewing habit dutifully suggests a new range of TV Shows for him to binge-watch later.
The world is generating a diverse range of data like never before. Over the last couple of years, 90% of the total data in the world has been generated. More than 3.7 billion people use the Internet today, and that number is only increasing. Google is processing more than forty thousand searches every second, while 41000 new pictures are being uploaded on Instagram every minute. By the time you’re done reading this paragraph, Uber riders would’ve taken more than forty-five thousand trips!
In this scenario, businesses have an unprecedented opportunity to capitalize on the vast amount of information they are gathering on their current as well as prospective customers. Social Media is analyzing the behavioral patterns of individual users and predicting their affinities with great accuracy. The entire world is moving towards a connected networking platform with the advent of the Internet of Things and Machine Learning techniques. Data has become the new oil, and Data Scientists and Analysts are expected to monetize this oil to the greatest extent possible. But this burgeoning sector is experiencing a shortage of an efficient workforce. The lack of data scientists has become a major constraint, and industries are clamoring for individuals who can make sense of the data they are amassing and provide tangible business advantages. There are a widening demand and supply gap in the market, and five years ago, IIM Calcutta, in conjunction with ISI Kolkata and IIT Kharagpur, had sought to capitalize on the mismatch.

That’s how PGDBA was conceptualized, in accordance to the industry demands while paying due heed to their suggestions. As the fourth batch prepares to venture beyond the gates of Joka, the last one and a half years of training imparted at these stellar institutions are going to be employed. The industry has steep expectations of this bunch of talented individuals. They’re expected to draw meaningful insights out of data that benefits their businesses. From risk management to healthcare analytics, to behavioral analytics and digital marketing; the needs that PGDBA graduates are expected to cater to are diverse.
As the world keeps amassing higher amounts of data, it’ll become increasingly difficult to make sense out of it. It’ll be akin to finding the precisely manufactured red coloured needle out of multiple piles of slightly deformed red coloured needles; surgical precision is critical to ensure it does not become a bloodbath. That’s where this course comes in, perfectly positioned to meet the business requirements by capitalizing on the technological advancements of the 21st century.


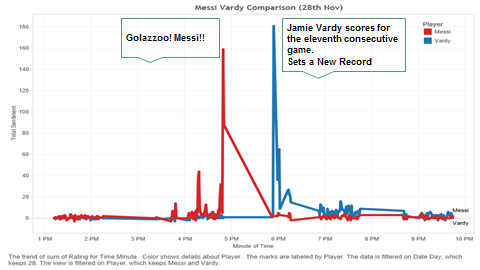 A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!
A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!