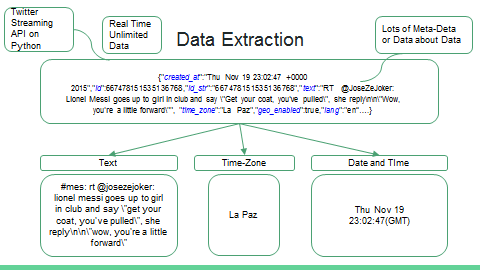
A peek into Team Tabs, one of the three teams representing India at DSG.
It was a crisp Friday morning and I was seated comfortably in the plush IIMC library. The PGDBA semester was well underway, assignments were raining thick and fast…life was busy…life was good and I was brimming with excitement.
I had only just begun working on a competition, which had started 4 days ago on June 14th 2016. It was an inter-university data-science competition called the Data Science Game. With so many constraints such as limited number of submissions in a day and final selection of only one team from a college, it was, by all means the “big deal” and a glance at the list of competing universities showed us some tough nuts. There were the usual suspects i.e. Stanford, Cambridge, Oxford et al., supplemented by a host of premier universities from across the world.
Certainly our team of four from first-ever batch of PGDBA, though no novices, were far from being among the best in the world… or were they?
And so we – Team Tabs – prepared a starting output, clicked on the ‘Make Submission’ button and waited with a muted yet expectation-laced anxiety that any Kaggler worth his salt would be familiar with and then this image popped up on our screen:
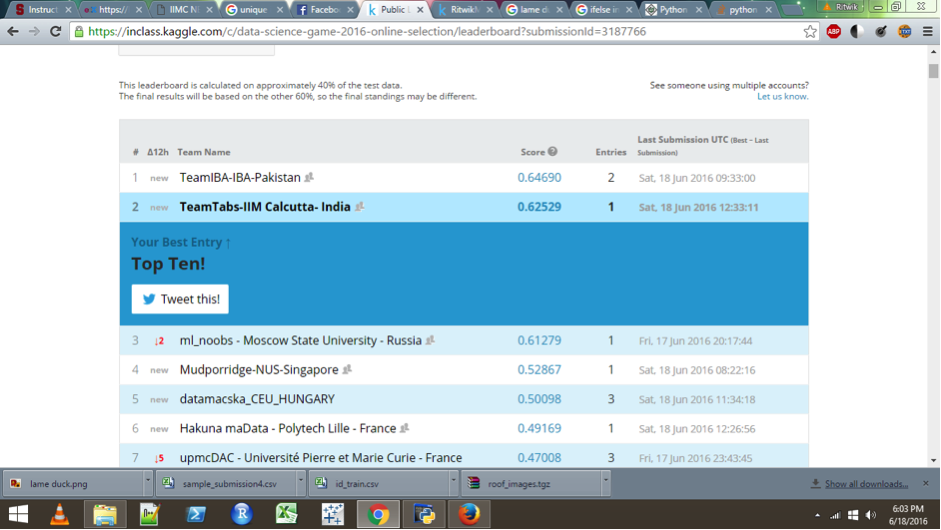
Most authors describe moments like these with the cliche ‘There was a moment of silence followed by….’ I discovered that they were quite wrong…as my uncontrollable Hagrid-like laughter filled the breadth of the IIM Calcutta library, defiant of the several bemused yet stern glares that were pointed in my direction! Second in the whole world! Irrespective of its ephemerality, irrespective of the pains required to maintain it or the challenges that we were about to face in the coming three weeks – it was a moment of reckoning for us, a moment to cherish, a moment to savour. Yet, when I look back I can say with certainty that it was at this point I started believing that international glory wasn’t beyond our reach.
What followed were some of the most gruelling days of my life. Over the next three weeks, we went on to learn and implement Deep Learning (Convolutional Neural Networks) algorithms for image classification. We travelled to multiple universities in a quest for servers to run these algorithms. We learnt, we toiled, we toiled hard and we thrived. When the competition ended, we were the top team from India – Yes! Our hard work and perseverance led to us being the Rank 1 Indian team. We were among the 20 teams from around the world selected to travel to Paris for the final phase of the competition and folks, as you read this article, we’re on the flight journey towards the finals of the competition in Paris, to be held on 9th September.
What fills me with even more delight is that not just us, but three teams from India have made it to the final 20 – one each from IIM Calcutta-Team Tabs, IIT Kharagpur and ISI Kolkata- The Frequentists (in their ranking order). India has made its presence felt in this 2nd edition of Data Science Game and interestingly enough, all the three institutes are what together constitute PGDBA! It is encouraging to see that three Indian teams have proved themselves worthy of being the global top 20 when 146 teams from 28 countries participated and showed their mettle in this grueling competition.
The competition contained an image classification problem. A set of images were given, which had to be classified into four categories. The problem at hand could have been done in various ways. We decided to use deep learning as a lot of interesting work is being done around it and it’s one of the most advanced techniques currently available. We had a basic knowledge about it and developed more understanding as we moved along. The process of compiling and executing codes went on and we worked hard every single day. The machine learning algorithms take time to execute and with limited computing power at our disposal and time constraint of the competition, we ensured that every iota of it was used. As we were fighting neck to neck with all top notch universities across the world, the task was not at all easy and there were a lot of hurdles on the way. The limited computing power slowed us down. Every iteration of the code required a whole day and thus constrained our capacity to experiment with the algorithm. Soon other teams caught up with us on the leaderboard. To wrinkle out the problems we went to IIT-KGP and ISI to gain server access. However, the terminals at both places were preoccupied. As a last resort, we decided to use Amazon Web Services (AWS). AWS was difficult to set-up because of the complex technicalities and as none of us was acquainted with the process, it made our job all the more difficult. We quickly took charge and read about it from the scratch, spending a precious time of 3 days to figure everything out and get it running. In hindsight, it was worth the effort. Our first run in AWS increased the accuracy by 5 % and it all paid off with the jump on the leaderboard.
Now that we look at it, a lot of edge was given to us by our PGDBA curriculum. The basics of machine learning and computing were well laid out throughout the course. It enabled us to deep dive into deep learning and comprehend the technical aspects around it. We also consulted with professors for guidance. With Team Tabs standing at 12 in global rankings, we realize that we have learnt a lot on the way, when we were actually working on the problem statement.
We will now be competing with some of the top Kagglers in the finals. The finale would certainly provide us with global exposure as we will get a macroscopic view of what’s happening around the world in the field of data science by interacting with top-notch data analysts spread across the world. Since it’s a 2-day competition, the dynamics of the game is bound to change. We haven’t been able to put in continuous concentrated efforts towards the final round owing to the rigorous academic curriculum this semester and us coping up on classes. We do have a lot to cover but we will keep learning new stuff as we have been doing in the past year. Thus a great opportunity for knowledge transfer and networking lies ahead. With everyone’s hopes in us, we make our journey to Paris, where the final leg of the competition awaits… along with our fateful turnout in the 2nd Data Science Game competition.
About the team – “Team Tabs” from IIM Calcutta
Pranita Khandelwal – She completed her graduation (B.Tech.) in Electrical & Electronics Engineering and Masters in Economics from BITS Pilani. Initial interest in statistics and then further exploration of online courses made her pursue a career in the data science field.
Ritwik Moghe – He is a Mechanical Engineer from IIT Madras. With no coding background in the beginning, he learnt everything after joining the PGDBA program.
Avinash Kumar – He is a Mechanical Engineer from NIT Jamshedpur and has worked in manufacturing industry prior to joining the PGDBA program. While in college, he participated in some analytics competitions and enhanced his data science skills after studying in the three institutes of PGDBA.
Rachit Tripathi – He is a Mechanical Engineer from IIT Kanpur. He has worked on multiple projects in Robotics, programing and data handling areas while he was in college. His keen interest in mathematics and computing drove him to join PGDBA.

Do check out the team from ISI at the link: The Frequentists



 A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!
A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!