
How my first machine learning model was validated by a goal scored a continent away.
Ritwik Moghe
It was the twenty-eighth day of November 2015. As the strangely balmy day yawned, stretched and gratefully gave way to dusk, several eyes were glued to the actions of one man. The man was slight, had strange spiky hair and a face that might remind many of all those ‘dawgs’ or ‘dealers’ from Breaking Bad. Only a year back, hardly anyone knew of his existence. And today, he was about to etch his name in the annals of footballing history.
As he latched on to a pitch perfect through-ball that split the Manchester United defense in half and slotted it in past the oncoming goalkeeper, several things exploded. One of those was the voice of the legendary Martin Tyler as he shouted “Vardy! Its Eleven, it’s Heaven for Jamie Vardy” (The goal as it unfolded). Jamie Vardy, a name most of you might still be unfamiliar with, had broken the English Premier League Record of scoring goals in most number of consecutive matches. He had scored in each of the past eleven games. In the grand scheme of things, the record, in itself might not be much significance. What mattered more was Vardy’s story. From an amateur player with no ‘proper’ training or facilities and very humble beginnings, he had risen to be the most prolific striker in one of the most competitive leagues around the world. It was a classic fairy-tale. For several amateurs trudging every evening into those muddy football fields and trying to curl it like Carlos, Vardy was hope.
So as he was being engulfed by his team-mates after he had scored that crucial record-breaking goal, Vardy was causing another explosion around the world. It was an explosion of hope, of greetings and of admiration. And sitting in our dorm rooms overlooking the ponderous Barrackpore Trunk Road in the quaint campus of ISI Calcutta, a bunch of us fledgling data-scientists of PGDBA captured this joyous explosion. We captured it using Twitter.
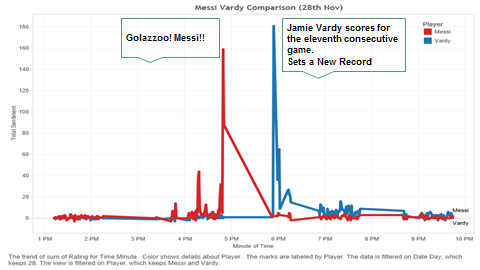 A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!
A graph encapsulating the positive Twitter sentiment about Vardy right after THE GOAL!
The problem that we were working on was Opinion Mining through tweets. Billions of tweets are posted every day. These tweets reflect the opinions or sentiments of the users about various topics. For instance, a tweet like “I love Apple #Iphone6” might reflect the user’s positive sentiment about the company Apple. A study of several such tweets about a particular subject or company can provide valuable insights to the company about the general public opinion about themselves.
We were analyzing the Twitter sentiment about various current and upcoming football stars. Our aim was to identify the next big star, the one who would eclipse Messi and attain the ultimate pinnacle of fame by someday being the brand ambassador of Tata Motors! Our observation about Vardy and his big day was a mere microcosm of a bigger project where we analyzed over one million tweets about 10 players obtained over a period of one month.
The analysis began with mining tweets about the particular players. The tweets were obtained from an API using Python. Relevant meta-data like the location of the user and the time-stamp of the tweet was extracted along with the text of the tweet.
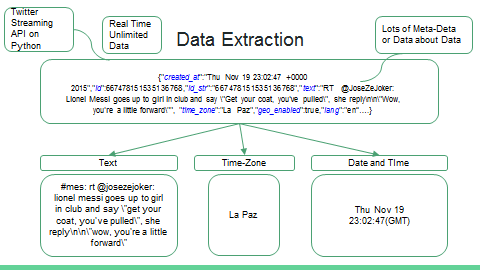
The text of the tweet was then converted into a Term-Document Frequency Matrix (TDF). Now only a year ago, all that I could I have thought of on hearing ‘Term-Document Frequency Matrix’ would have been Neo in his slick glasses staring into some green numbers floating Chinese-style on an antique nineties monitor! But TDF is way simpler than that. All it does is that it creates a table. Each row is a tweet. All the words observed in all the tweets that we are studying make up the columns.
Consider this example for clarity-

Thus each word is now a feature and each tweet a data-point. We then used a Machine Learning technique called Maximum Entropy Classifier in R to classify each tweet or data-point into one of the three categories: Positive, Neutral or Negative. (I could get into the details of the work, about why we went for supervised classification approach, about why MaxEnt works best for Text Classification etc. But since I’m trying to make this article tractable for someone with no prior analytics experience I stop by providing a link to another blog about our detailed work. (A detailed report of our project)
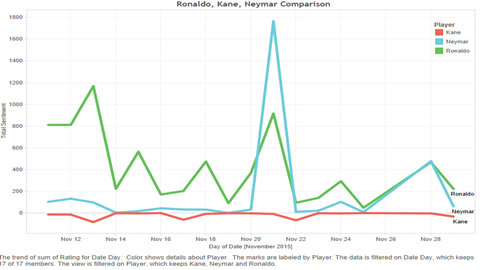
Now this process was carried out for all the tweets about all the different players. The prevalent sentiment about a particular player was given by the difference between the number of positive and negative tweets (which was also normalized). Doing this helped us observe several interesting trends in the data. Consider the comparative study of sentiments about Neymar, Ronaldo and Harry Kane over November 2015. Also, have a look at how the sentiment about Harry Kane varied across countries.
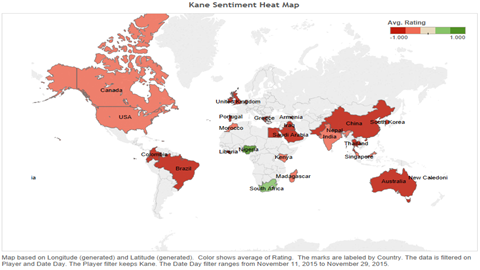
Such analysis has huge potential applications. Imagine how Tottenham Hotspurs, the club which Harry Kane plays for could maximize their profits by opening more ‘Spurs Stores’ in South Africa where Kane is way more popular (green) as compared to say Australia where he is clearly notorious (red). Are you an executive at EA Sports and want to decide whom to have on the cover of FIFA 16? Just mine sentiment on twitter and viola, you’ll see that Neymar would be a way better choice than Kane.
So this was all about our project on Twitter sentiment about football superstars. This project was a part of our course called Computing for Data Sciences at ISI Kolkata. All of our fellow mates from PGDBA have also worked on several such (hopefully: P) interesting projects. Some of them will share their stories with you on this blog as well.
Vardy and his record holds a special place in our hearts. He was the perfect muse for demonstrating the effectiveness of our model. When you’ve come up with your first ‘Real’ model, the true test of the model happens when you see it work in real life on a completely unexpected scale. That meteoric rise in Vardy’s sentiment at 5.55 pm BST, right after he had scored the crucial goal proved to us beyond doubt that our model worked! So, I sign off with a link to that moment when Vardy smashed a record, the moment when people around the world celebrated the dawn of a new star, and the moment when our model was validated! Cheers!



